ByeType vs Typeless vs Wispr Flow — Built with Claude Code in 7 Days
Wei-Ren Lan
Voice input on current phones and laptops still isn’t very smart — it often misrecognizes technical terms and can’t adapt intelligently to context. Over the past 2–3 years, with the maturation of AI speech recognition and LLM technology, many vendors have started extending these capabilities to enhance voice input. While Apple has begun rolling out Apple Intelligence in the past year or two — enabling real-time speech recognition and LLM processing on capable devices — the system’s built-in voice input still hasn’t satisfied users. . Even 3 years after ChatGPT launched, if someone had told me that an engineer who only knew AI algorithms/applications and Python could build an AI voice keyboard app in Swift in one week — I would have found it completely unbelievable.
But here we are on 2026/02/22, less than one year after Claude Code launched on 2025/02/24. I completed this possibility experiment over the 7-day Lunar New Year holiday of 2026.
Thanks to the knowledge abundance brought by Transformer/LLM/Agentic Engineering.
Table of Contents
- Results
- Investment
- Why Did I Start?
- Competitor Landscape
- Technical Overview
- Agentic Engineering
- Closing Thoughts
Results
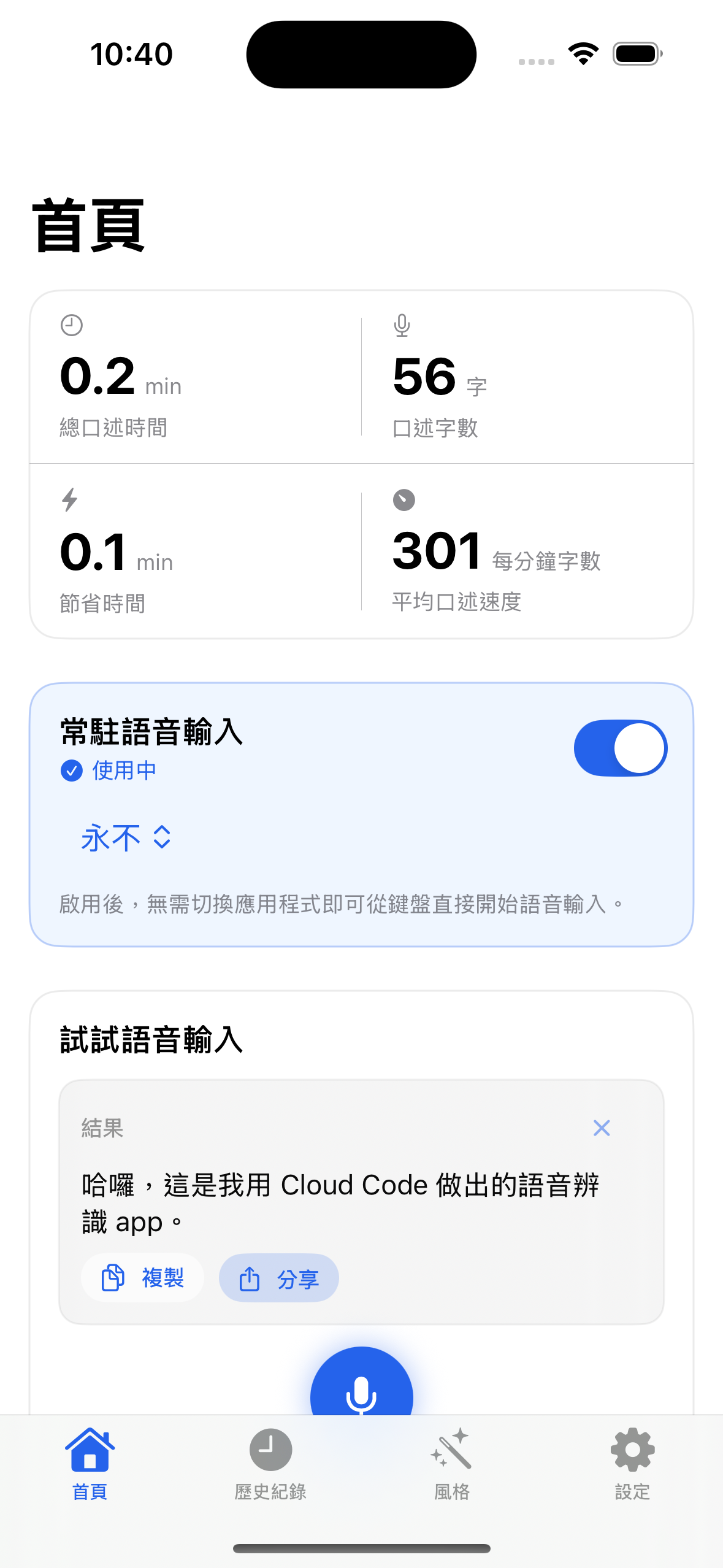
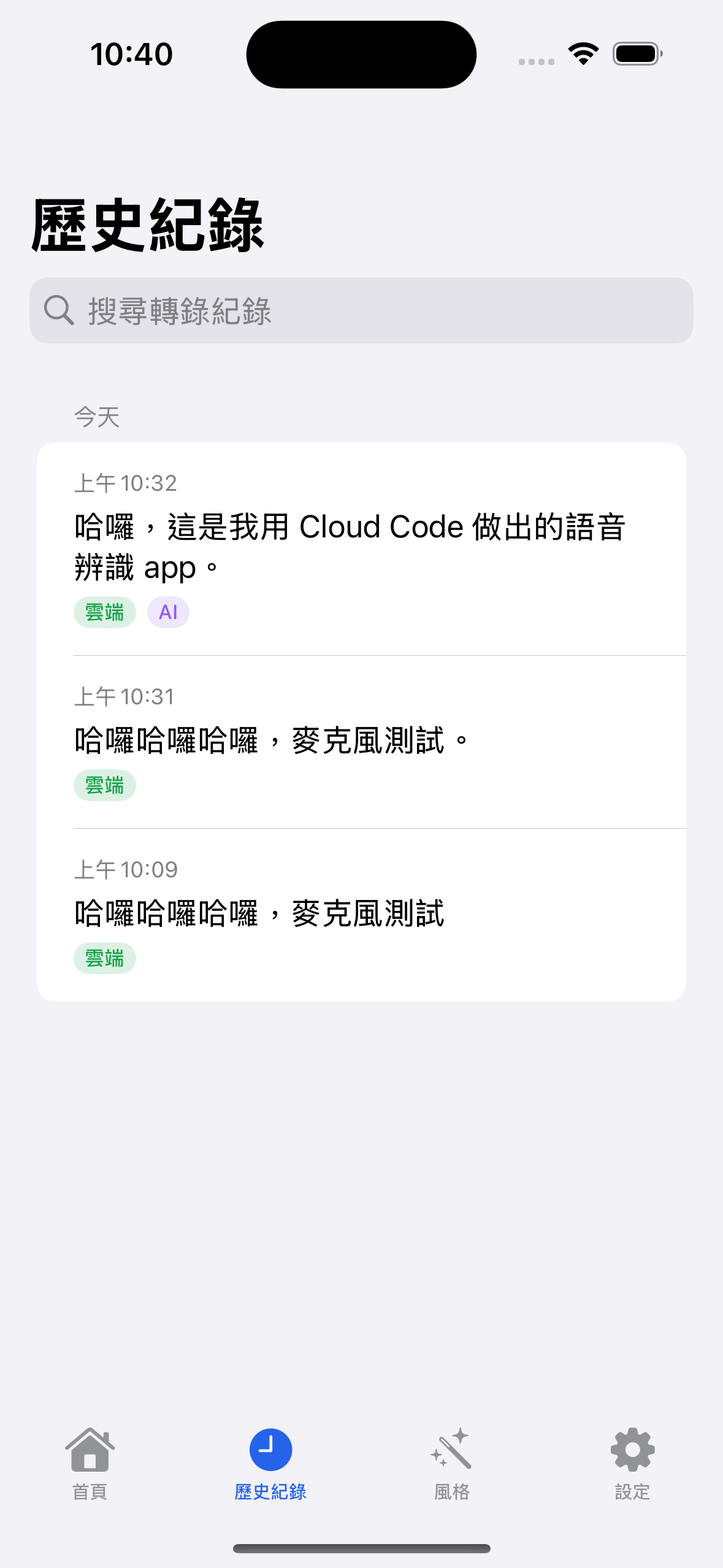
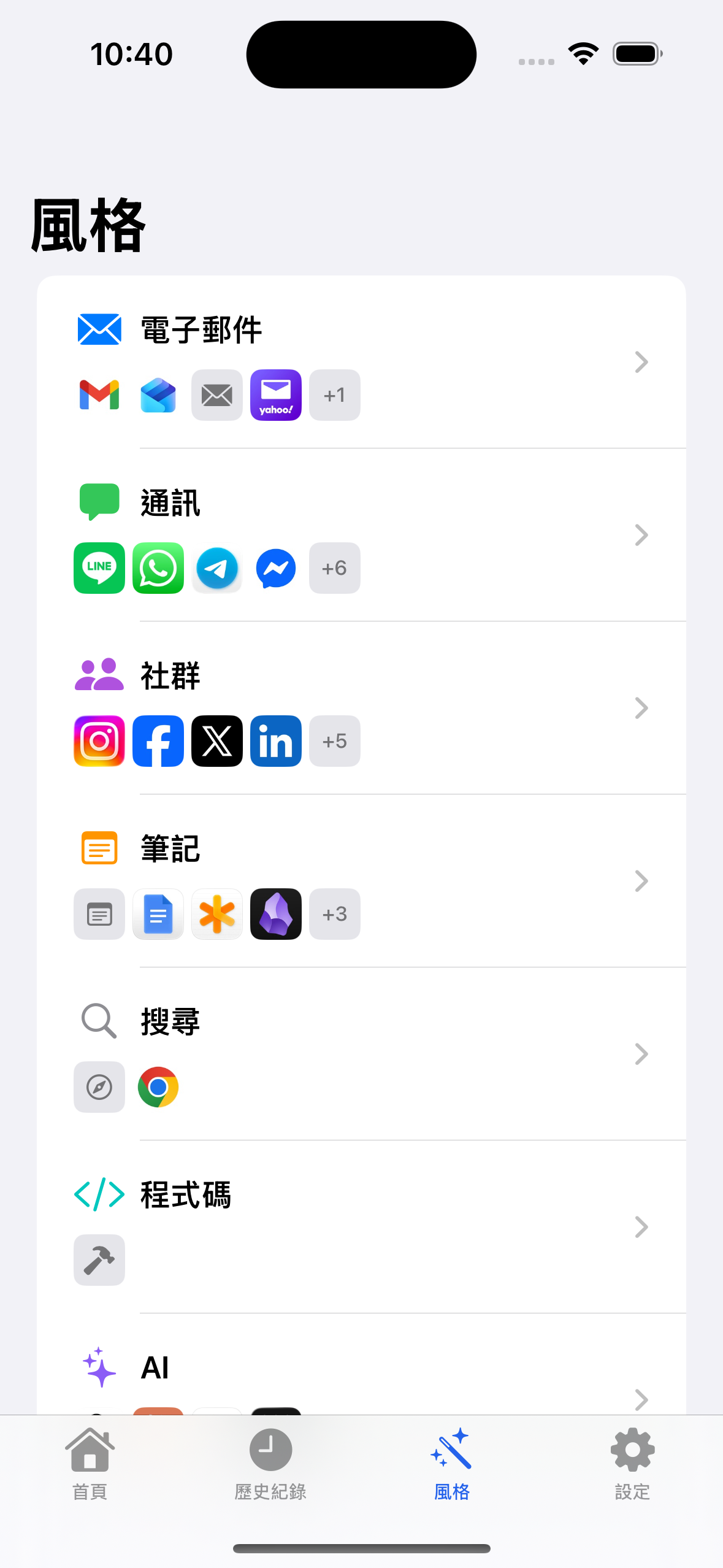
- A Swift-based iOS custom keyboard app with the following features:
- Real-time speech recognition + context-aware style refinement
- Technical terminology correction
- Voice-command text editing: modify recognized text by speaking your edits
- Customizable style prompts
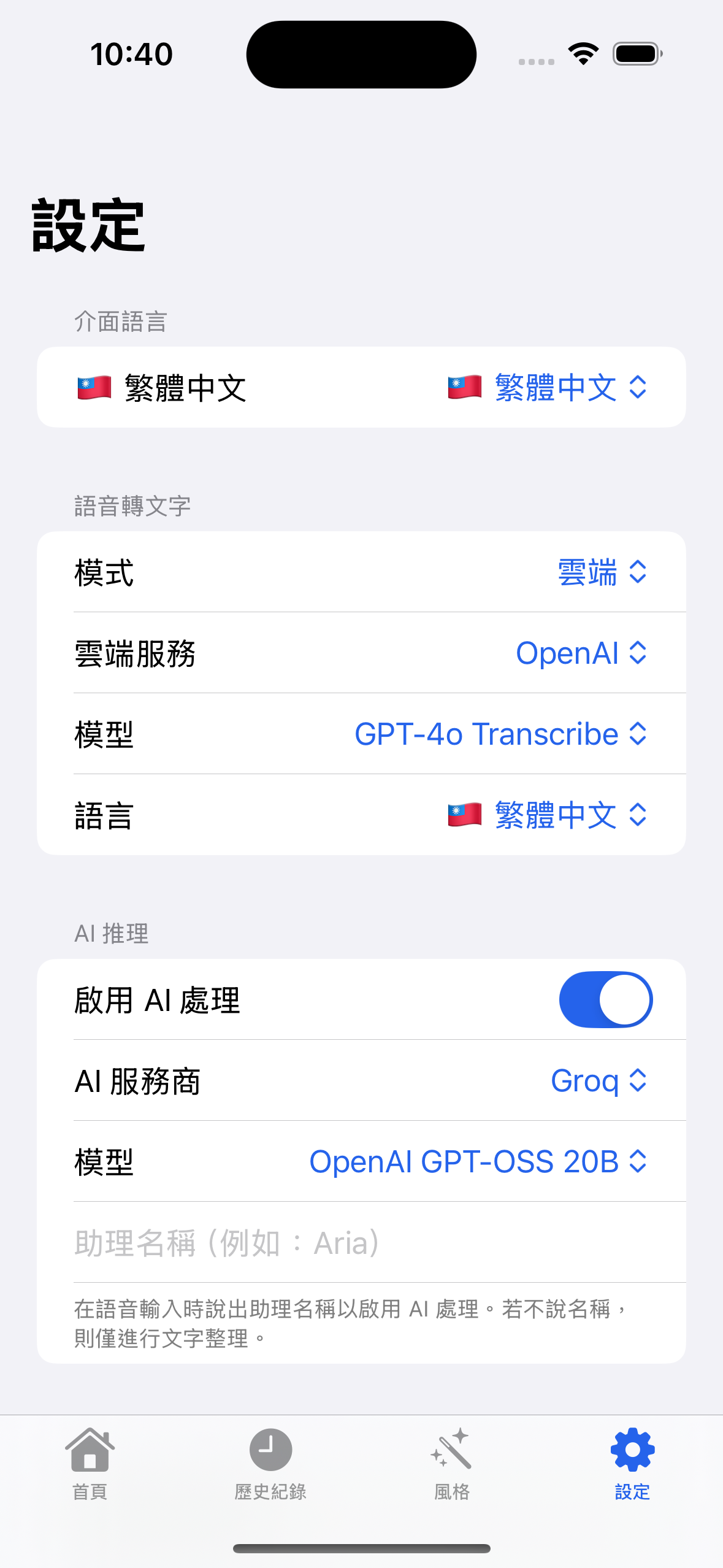
- Supports local WhisperKit model + cloud vendors (OpenAI/Anthropic/Gemini/ElevenLabs)
- A Landing Page deployed on Cloudflare Pages https://byetype.com/
- Hosted on Cloudflare Pages
- Multi-language support
- Home / Features / Privacy pages
Investment
- A 7-day sprint by an engineer with 7+ years of AI audio application experience
- Background in EE/Biomedical Engineering, proficient in engineering and debugging
- Claude Max: US$100
- Claude Code Extra Usage: US$230

Why Did I Start?
On February 10, 2026, a Japanese team shared on X (formerly Twitter) an analysis of Typeless — an AI Dictation tool that has been gaining traction across Asia. The analysis revealed that Typeless uses cloud-based speech recognition and may collect contextual data including full URLs, foreground app/window titles, on-screen visible text, clipboard contents, and system-level keyboard events. Additionally, the local DB may store transcription content and browsing data in plaintext — a potential contradiction with their “Zero data retention” marketing claim. When high-sensitivity permissions (Accessibility/screen recording, etc.) coexist with insufficient operational transparency, the overall risk is amplified, and users should pay close attention to data flows and permission scopes.
Based on years of experience building AI application products, I had a rough idea of how AI Dictation tools work: Speech recognition produces a transcript; combined with the user’s current app context, both are then passed as a prompt to an LLM for formatting and refinement.
After surveying the market, I found no open-source iOS solutions available. Curious about what it would actually take to build one, I started coding.
Competitor Landscape
As of February 2026, this market is already highly competitive. In the primary market (US), strong products already exist: WisprFlow and Willow, which raised $30M and $4.2M respectively in 2025. When AI luminary Andrej Karpathy coined the term “Vibe Coding” and it swept through the developer community in 2025, voice input became a standard tool for Vibe Coding. He also promoted another service at the time: SuperWhisper
Both teams are remarkably young — WisprFlow’s founder is just 27, while Willow’s two founders are 20 years old and dropped out of Stanford.
I’m particularly impressed by the energy of the Willow team. Founder Allan Guo has been a natural problem-solver since childhood: at age 10, he loved EDM and built a YouTube channel with over 10,000 subscribers earning $3K/month in passive income; by 15 he was using the GPT API; by 16 he was earning $30K/month selling e-books via GPT. Their self-given titles are brilliantly fun: “Chief Keyboard Killer” and “Chief Microphone Officer.”
Many major model companies in China have also launched AI voice input:
- Zhipu AI: AutoTyper
- ByteDance: Doubao Voice Input
The Asian-familiar Typeless is actually a late entrant — launched by a Chinese-American team in late 2025, primarily targeting East Asian markets outside China.
Beyond the well-funded products above, several indie developers offer open-source desktop (macOS/Windows) solutions prioritizing local models, such as Handy and OpenWhisper.
Core features are roughly the same across the board: (1) high-accuracy speech-to-text, (2) LLM-based formatting, (3) technical terminology correction. Since the underlying technology is similar, the meaningful differences come from the experience design — brand identity, interface character, ease of use, recognition speed, and overall workflow.
The current competitive moat comes down to who can capture user mindshare and build trust. Hence why WisprFlow and Willow have pursued ISO 27001, SOC 2 Type II, and HIPAA compliance.
If you’re interested, check out my AI Dictation competitor overview (in Traditional Chinese):
- https://docs.google.com/spreadsheets/d/17x49TAXIoL1Tyz9yl2S15w21hw25E8jqBhTXRqOLAao/edit?usp=sharing
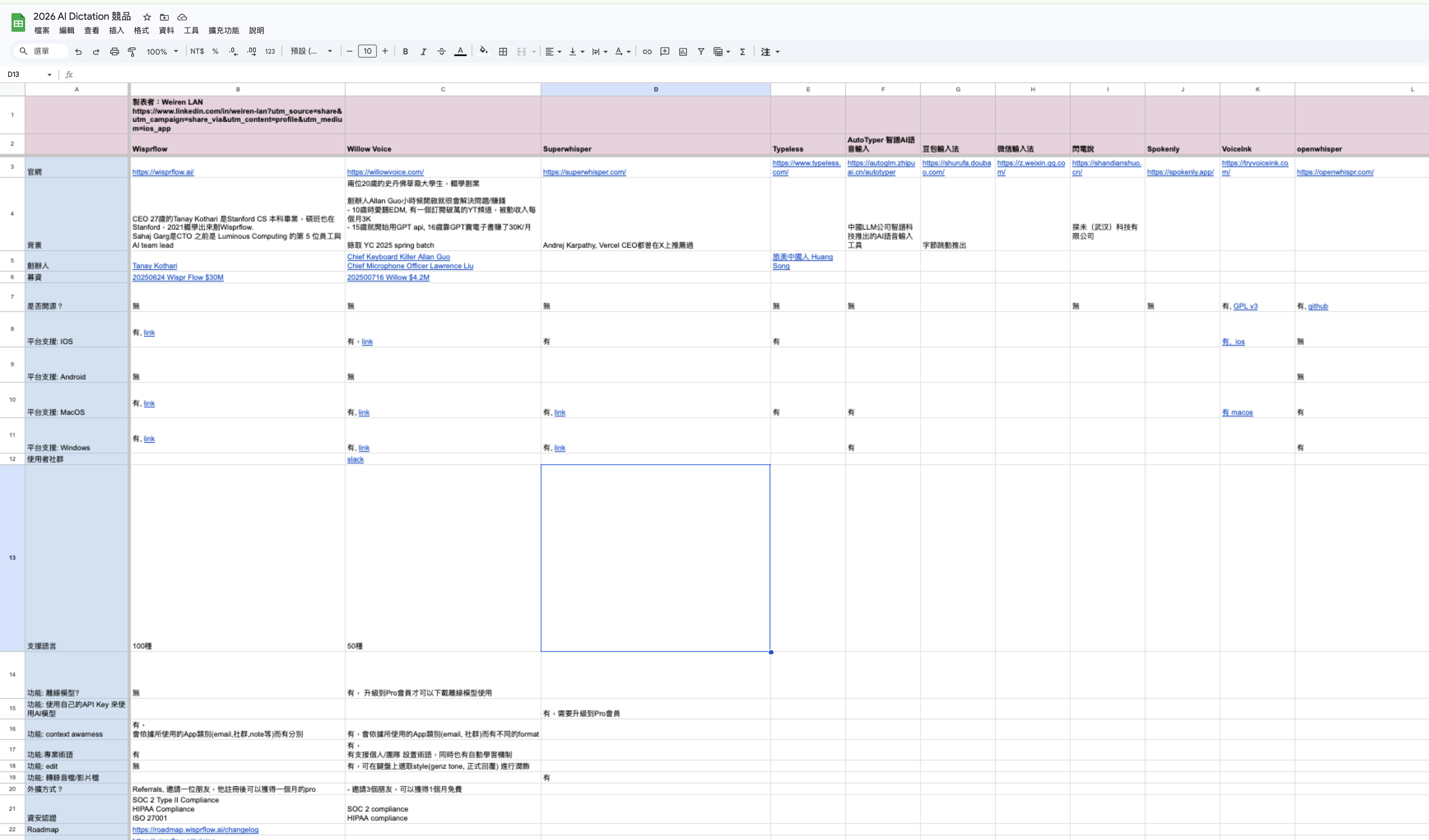
Summary:
- Mature technology, minimal feature differentiation — a fiercely contested product race
- User experience and user acquisition are the key differentiators
- Platforms like iOS are beginning to support on-device (Edge) recognition
Technical Overview
The technical core of AI Dictation: (1) Speech recognition model (2) LLM
Pipeline: a. User presses the custom keyboard to trigger recording b. Audio is sent to the speech recognition model c. Via system APIs, retrieve the app category the user is currently typing in (mail, notes, search) to understand the context d. Pass the speech recognition transcript and a context-appropriate format prompt to the LLM for refinement
The two primary requirements for this pipeline: a. High accuracy b. Fast completion time
You can use benchmark sites to find the right vendor: https://artificialanalysis.ai/
An additional consideration: c. Privacy
The current best option for iOS is Argmax’s optimized WhisperKit.
Agentic Engineering
Starting entirely from scratch with Claude Code is genuinely challenging. Even though Claude Code has a built-in Plan mode, it’s still insufficient to support complex architectural implementation on its own. That’s why we need to prepare usable tools and workflows for Claude Code to reference.
Context
-
Foundation Context: references for core features and architecture
- Goal setting: building an iOS AI dictation feature in Swift
- Reference architecture preparation:
- The open-source AI dictation tool openwhisper (desktop macOS/Windows, written in TypeScript)
- WhisperKit usage examples: https://github.com/argmaxinc/WhisperKit
- API documentation URLs and GitHub sample code for each AI vendor
-
Screenshots from various AI Dictation apps: Onboarding / Home / Settings / Custom Keyboard pages
Tool Setup
- Skills for Claude Code
- ui-ux-pro-max-skill: Evaluate and optimize interface design, refine user experience.
- compound-engineering-plan: A software engineering workflow skill from the Every.to team — covers the full plan/review/work cycle.
- MCP
- Context7: Fetch documentation for dependencies and libraries.
Other Tools
- Entire: GitHub’s former CEO Thomas raised a $60M seed round to tackle this problem, founding entire.io. What does it record? a. The coding agent session conversation for that git commit b. How many tokens were burned c. How much time elapsed d. How many steps were executed Very easy to set up — just follow the GitHub instructions in your repo and Entire will automatically link with your git commits.
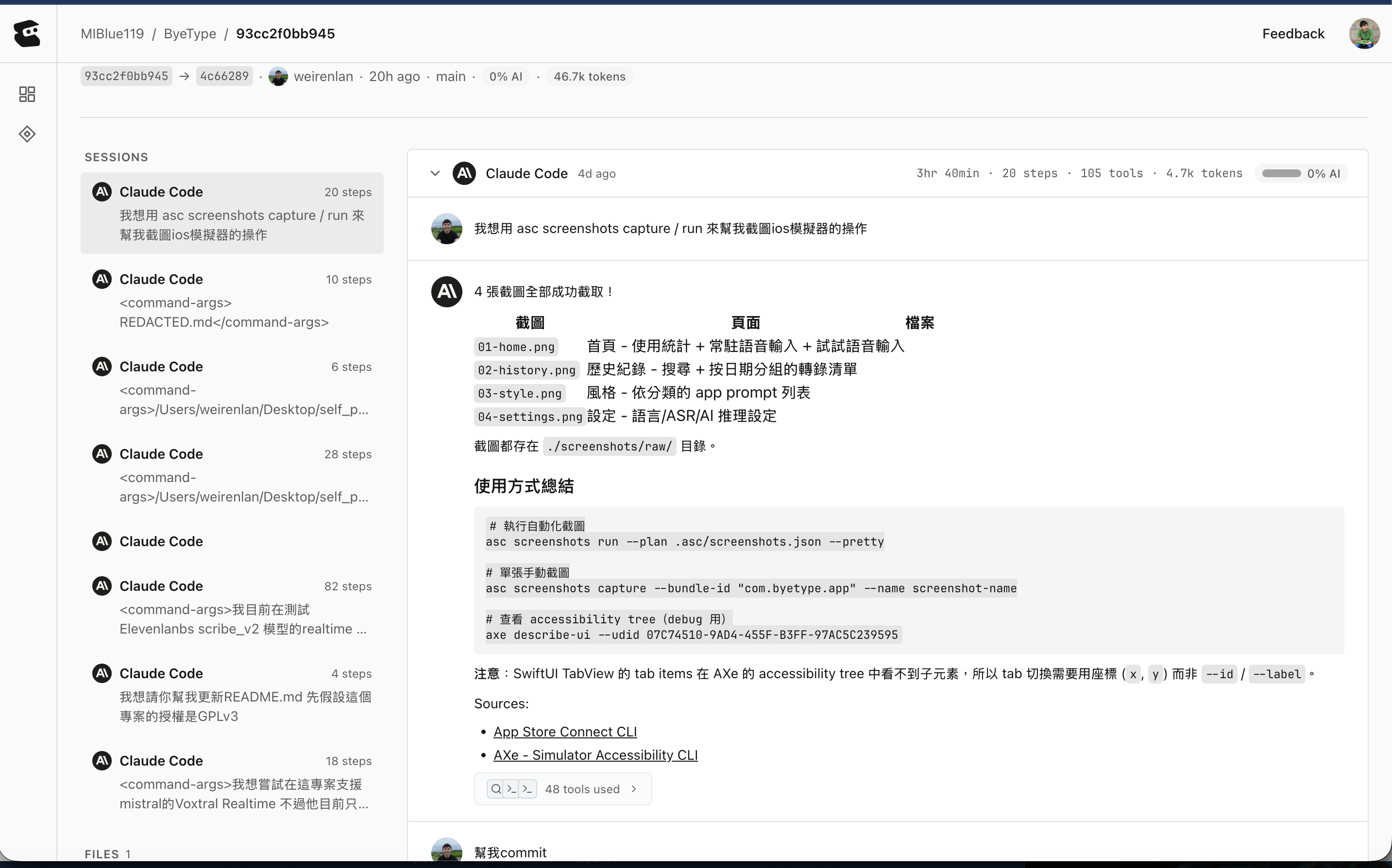
-
GitHub Actions: for basic CI/CD
-
App Store Connect CLI: Automate App Store workflows, including automated screenshots. Can be paired with Claude Code: “Please take screenshots in the simulator using asc screenshots”
-
Codex: the bench player — when Claude Code hits its token limit, Codex steps in for simpler tasks
-
ChatGPT: Web Search / Deep Research for background information — understanding App Store submission processes, OAuth design, etc.
Base Environment
- Xcode: Responsible for app compilation and deployment
- iPhone: For testing the app
- GitHub: CI/CD and codebase version control
- Apple Developer: Developer membership required for app distribution
- Cloudflare Pages/Domain: Deployment environment for the landing page
Development Workflow
- Compound Engineering Plan — plan features/feature tests; outputs a markdown plan for human review
- Compound Engineering Review feature
- Compound Engineering Implement
- /ui-ux-pro-max-skill — UI/UX optimization pass
- Human testing
- Once feature tests pass, run git commit to trigger CI/CD
Model Selection
- Preferred: Opus 4.6 — compared to Sonnet, it maintains better consistency across information gathering, planning, and implementation over long sessions.
Pitfalls
-
App Feature State Management: Agentic Coding tends to have gaps here. The core architecture flow still needs to be clearly described in natural language by a human. Without this, it’s easy to trigger loops — or you think something is done, but the recognition result from a previous session shows up again the next time you open the app.
-
Audio Processing Knowledge: You still need to understand audio sampling rates and format differences, since ASR vendors have specific supported sampling rate and format constraints.
-
Impact of New Feature Additions: When implementing a single feature, it’s easy to lose sight of the overall flow. You still need to verify that previously implemented features continue to work after adding new ones.
Closing Thoughts
This 7-day Lunar New Year hackathon was a magical experience. You can truly feel how Agentic Coding amplifies your capabilities — like entering a hyperbolic time chamber that lets engineers rapidly dive into unfamiliar syntax. The dopamine hit from Claude Code’s output had me hooked, waiting eagerly for each new result. The software engineering experience and processes accumulated over the years still matter greatly — they let you move steadily forward and quickly identify the likely causes when bugs arise. But for understanding advanced optimizations and features — such as memory usage, UI/UX design, and integrating membership systems with payment processing — deep domain expertise is still essential.
Happy Agentic Coding to everyone!
I’m Weiren, an engineer with 7+ years of AI systems development experience, specializing in speech recognition, audio intelligence, and on-device machine learning. Let’s connect: https://www.linkedin.com/in/weiren-lan/
Wei-Ren Lan
7+ years building production AI systems, specializing in speech recognition, audio intelligence, and on-device ML deployment. Previously led an AI team shipping ASR, speech denoising, and real-time inference to production. ByeType combines years of hands-on voice technology expertise into a voice input tool that actually works.